Starting Point
- The AI system, developed from earlier projects, had grown increasingly complex.
- This complexity resulted in non-reproducible results.
- Various parameter adjustments were attempted, but no significant improvements were achieved.
- Expansions involved adding new sensors, but the results were anything but comprehensible.
AI Rework
A fundamental rethinking was necessary to simplify the design, improve reliability, and create a more robust and understandable AI, ensuring consistent and dependable results.
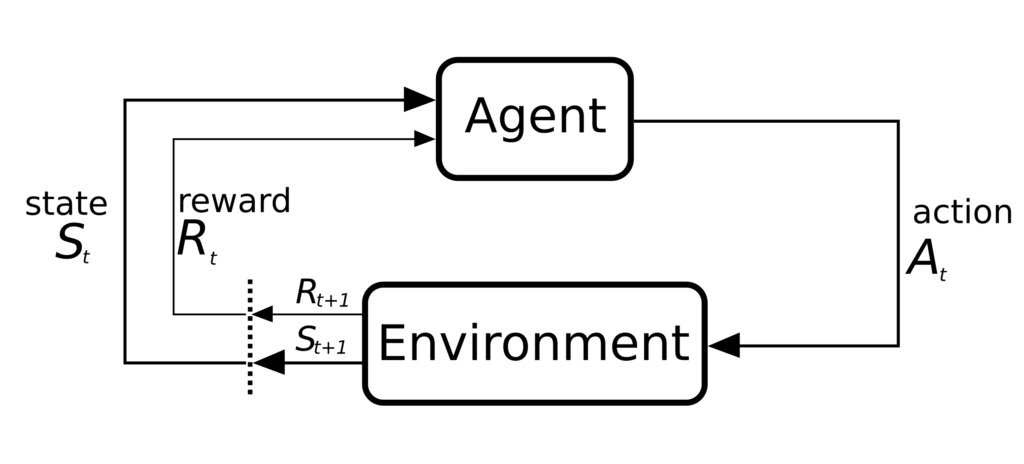
Source: commons.wikimedia.org
{kind=link}
Agent
The Agent is the brain of the hexapod reinforcement learning system. It utilizes reinforcement learning techniques to teach the hexapod how to move effectively. A neural network based on deep Q-learning is used for decision-making.
Key Functions
- Initialization: Sets up the agent with an initial state and random reward values.
- Training: The agent explores various movements and learns from the rewards it receives. Over time, it shifts from exploring new actions to exploiting the best-known actions.
- Decision Making: The agent decides on movements based on a balance of exploration (trying new actions) and exploitation (using known good actions), based on the results of the neural network.
- Learning: The agent updates its knowledge base with the rewards from its actions, refining its understanding of which actions yield the best results.
- Model Management: The agent can save its learned model to a file for later use and load existing models to continue training or for testing.
Training Process
The agent undergoes multiple episodes of training, where it continually improves its ability to make optimal movements based on the rewards it receives.
Testing Process
After training, the agent’s decision-making process is tested to ensure it can consistently make the best movements.
Environment
The Environment class acts as the interface between the agent and the hexapod robot. It abstracts the hardware control, making it easier for the agent to interact with the hexapod.
Key Functions
- Initialization: Sets up the connection to the hexapod robot.
- Servo Control: Sends commands to the hexapod’s servos to move its legs.
- Reward Calculation: Evaluates the hexapod’s performance based on its height and assigns a reward. This feedback is crucial for the agent’s learning process.
Interaction with the Agent
The environment provides the agent with the necessary tools to control the hexapod and receive feedback on its performance. This interaction is fundamental to the reinforcement learning process.
Reward Function
The reward function is part of the environment and provides feedback to the agent based on the previous actions taken. During training the agent tries to maximize the reward. It is important that this function does not have local maxima that give the impression of an reward wise optimal state without actually being one.
Angle Reward
The simple Hexapod reinforcement model adapts the state space table with the rewards. The state space consist of 20 values per tibia and femur and can therefore be plotted three dimensional. The untrained rewards over the state space is depicted in the following image:
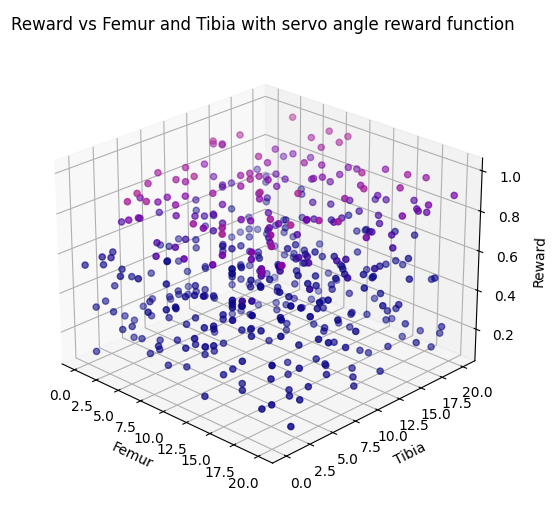
The simplest goal of the Hexapod system is to stand up from laying on the ground. This can be incentivized by a reward function that maximizes the angles of all arms. The implementation only considered the arm position of arm 0 and controlled all other 5 arms with the same movement sequence as arm 0. The following image shows the learned reward after 45 minuets of training.
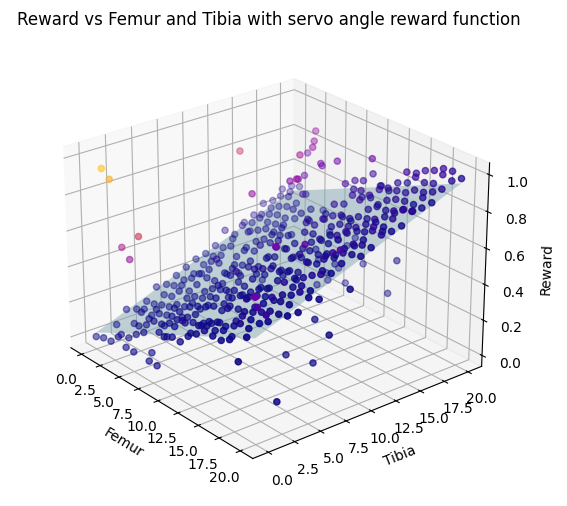
Here can be seen that the reward increases with any of the angles and reaches its maximum when both arms are at the position 20 which corresponds to fully stretched out arms. An advantage of this simple reward function is that there are no local maxima that can inhibit the learning process.
Height Reward
In the next step a updated Model that facilitates a neural network was used. Since the initial training process did not bring the expected results the height reward function was examined regarding their local extrema. For this the height function that resembles the reward was modeled as follows:
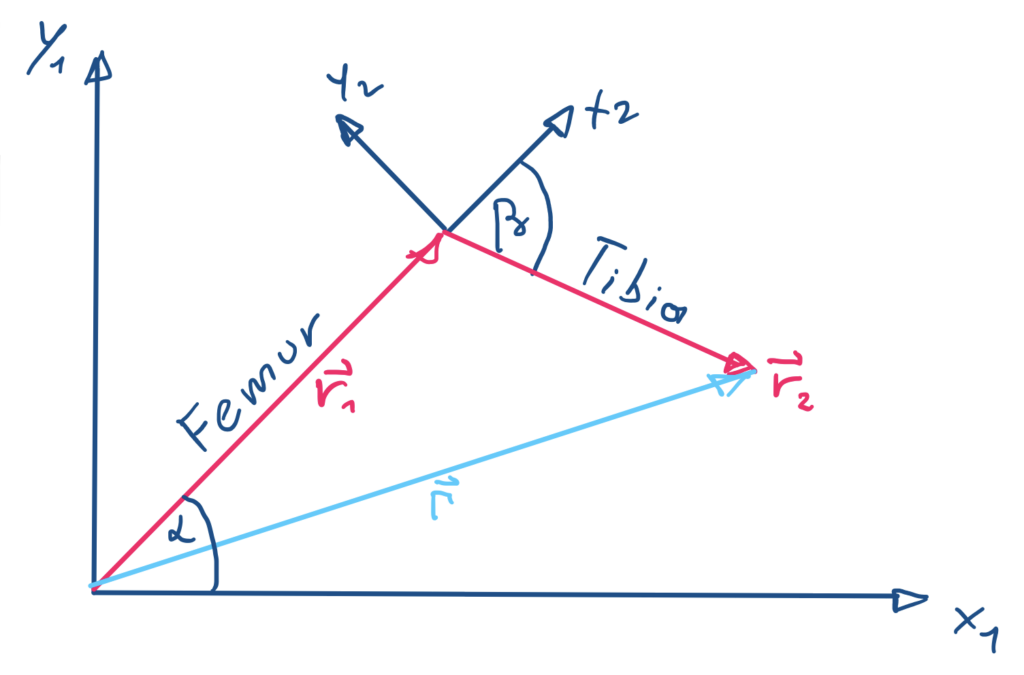
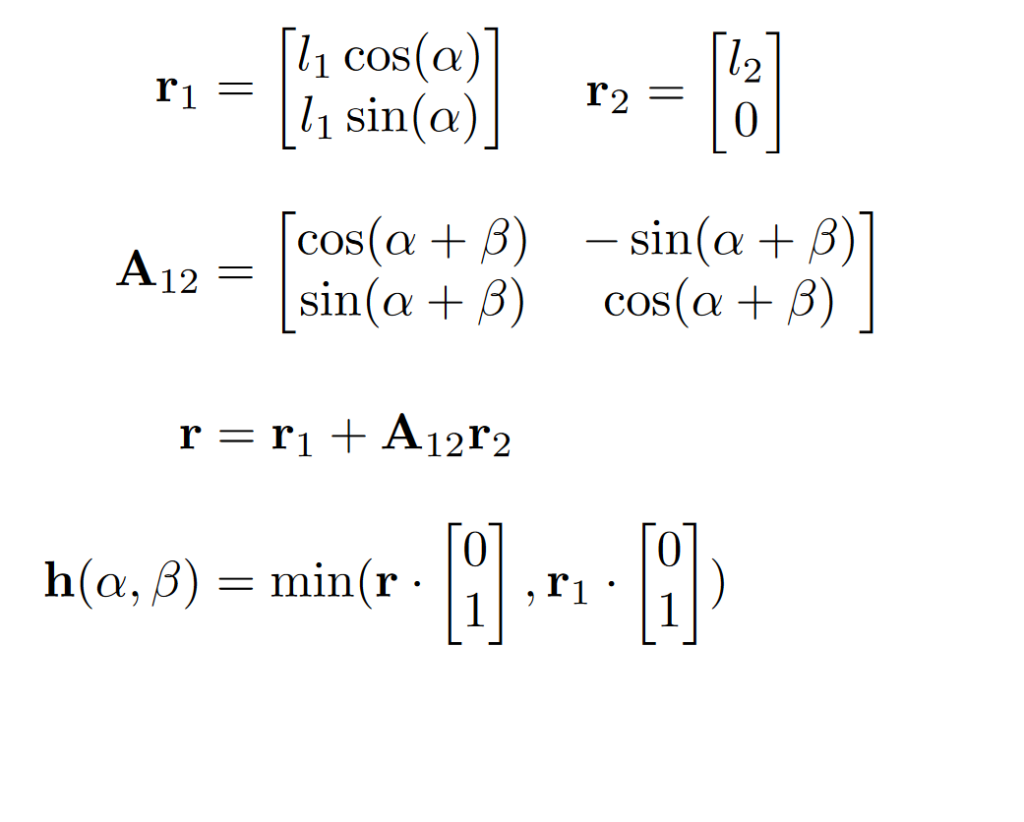
The function h is as a three dimensional plot in the following image with the state space parametrized with the angles alpha (femur) and beta (tibia):
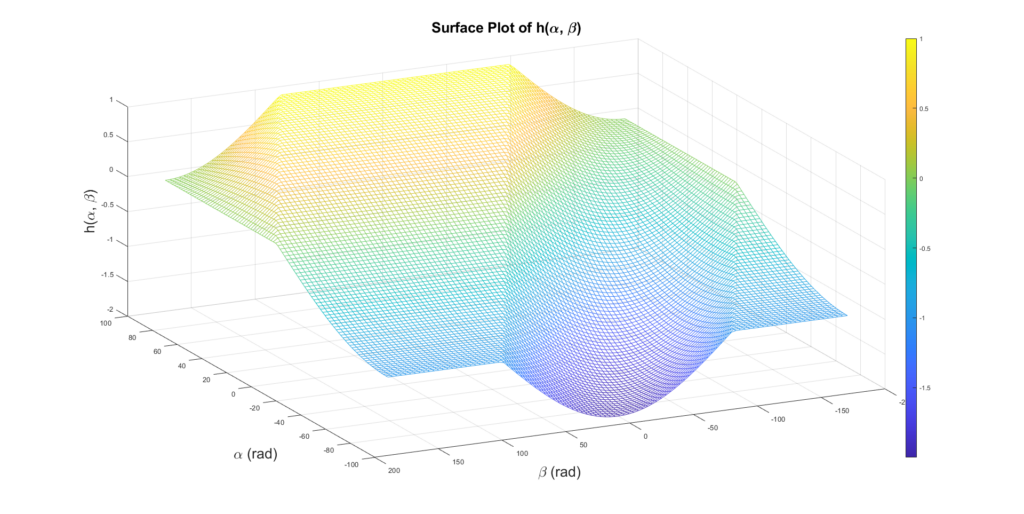
One can see that the height does not change in the left and right corner of the diagram (low angles of the femur) since a change in the beta then does not alter the height of the Hexpod in this part of the state space (saddle point). Consequentially the agent has to explore outside of this region to be able to find the global minimum that corresponds to the Hexapod standing upright. This can be achieved by either additional constraints for the angle movement or through a policy with a higher incentive for state space exploration.